问题
Scrapy中对请求的去重是通过计算一个request的fingerprint,并放到一个set中来实现的。代码如下:1
2
3
4
5
6
7def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
Scrapy-Redis也是如此, 只不过这个Set是放在了redis中1
2
3
4def request_seen(self, request):
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
这里存在一个问题,fingerprint计算出来的是一个长度为40的ID,So,假设有1000W个请求,那么暂用的内存空间是1000W*40Byte = 400M.
解决方案
于是就想到了BloomFilter,它的算法其实很简单,就是创建一个m位的bit数组,每一位都初始化为0,然后选择k个Hash函数,针对一个字符串,用这k个hash函数分别计算得到一个index,然后将index对应的bit置为1.这是加入字符串的过程。那么如何检查一个字符串是否已经存在呢,也是按同样的方式计算得到k个index,如果这k个index对应的bit中有一个不是1,则该字符串肯定不存在,如果全部为1,只能说有一定的概率存在。这个算法中最关键的就是这个概率,只要这个概率足够大,不一定要100%,因为爬虫是能够容忍一点点错误的,大不了少爬几个页面。关于BloomFilter,下面几篇文章我觉得介绍的很清楚,里面的参考资料也挺有价值。
实现过程
我向来都懒得重复造轮子,好吧,我就是懒。看了几个开源项目的代码,取其精华,为我所用。
1、jaybaird/python-bloomfilter不仅仅实现了BloomFilter,还实现了一个大小可动态扩展的ScalableBloomFilter
2、t-mart/bloomfilter,优点是Hash函数可以自己通过注解的方式配置,比较灵活。
然这些代码都只是在本地内存中保存bit,不太适合应用在现有的分布式爬虫中,然后,我又去开源世界索取了。xupeng/bloomfilter-redis通过pipeline直接在redis里批量执行setbit,getbit实现了bloomfilter.最终决定借鉴2的方式改写下bloomfilter-redis,实现hash函数可配置,用到我的爬虫中去。
在打算编码之前发现了scrapy-redis的一个问题,图1是redis中的DupeFiler,图2是scrapy-redis中的,明显破坏了原有框架中DupeFiler的可扩展性,导致我要改用BloomFilter的话需要额外重写跟多代码。
图1: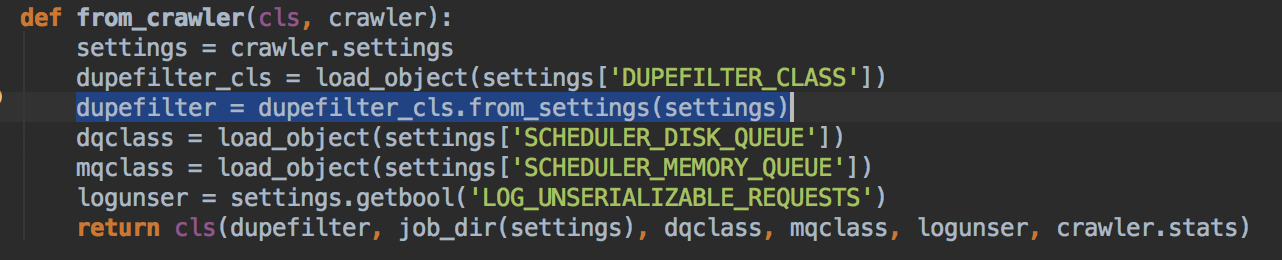
图2: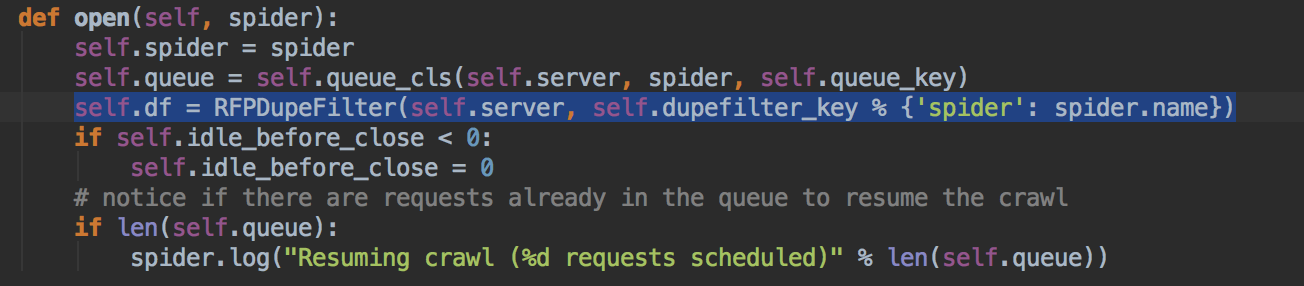
后来发现已经有人问了跟我一样的问题https://github.com/rolando/scrapy-redis/issues/37, 作者也承诺后面会Fix,所以,不急,后面等他们更新了我再改(主要功能都OK了,就是现在没法通过配置文件配进去)
结束
BloomFilter告一段落,接下来会去看看request增长太快的问题。