纯粹个人笔记,为什么要写博客?强化自己学习的知识点。实践过的东西才最深刻,但很多知识平时项目中不一定有机会实践,所以唯有自己能够写下来、描述清楚才是真的理解了。
CPU的计算性能已经远远超于内存的访问性能,所以芯片设计上用了很多手段来减少他们之间的gap,最主要的办法还是加了多级缓存, 如图所示:
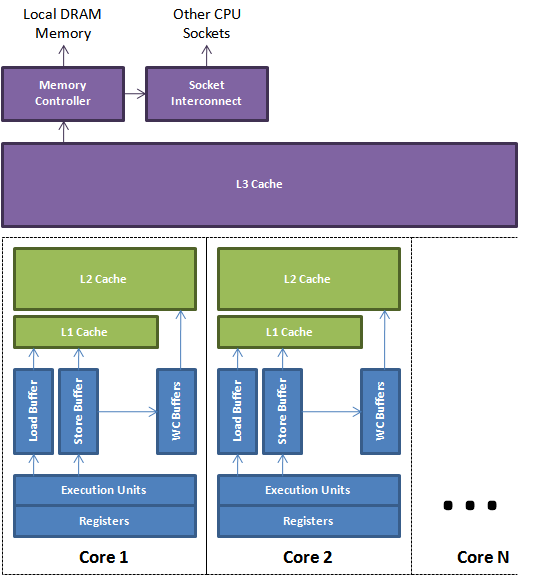
图片来源 http://mechanical-sympathy.blogspot.com
Java内存模型也类似,下面是一个更加抽象的图: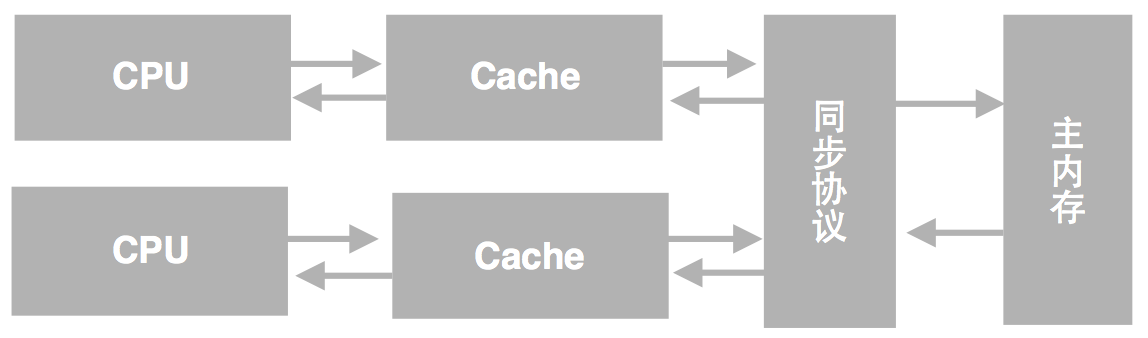
图片来源 http://tech.meituan.com/
这个模型存在一个问题,当多个线程共享主内存中的一个数据时,各个CPU的缓存有可能是不一样的,存在数据不一致的问题。
volatile 的作用就是让所有线程在同一时刻看到的共享变量的值是一致的。当对volatile变量进行写操作时,线程所在的CPU核心会将当前缓存的这个变量数据写会到系统内存,这个写会内存的操作会引起其他CPU核心里缓存了该地址的数据无效,这样当其他线程操作该变量时,由于缓存失效,就会从主内存重新读取,从而保证了数据的一致性。
Java内存模型[3]中的几种Happens-Before Relationship,有一条就是针对volatile的。A write to a volatile field happens-before every subsequent read of that volatile.(对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作)。这里的happens-before只是一些标准而已,并不是具体的实现原理。
还有一条Happens-Before Relationship规则就是
An unlock on a monitor happens-before every subsequent lock on that monitor.(对一个监视器锁的解锁 happens-before于每一个后续对同一监视器锁的加锁)
从这条规则就可以看出,为了确保所有线程看到的同个变量的值是一致的,可以使用volatile变量,也可以用锁。
但是 volatile仅仅保证数据的可见性,并不能保证互斥性, 下面这段代码是有问题的,两个线程同时操作count, 最后的结果是不可预见的, volatile并不能保证count++是一个原子操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Test{
public static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
Runnable runnable = new Runnable() {
public void run() {
int i = 0;
while (i < 10000) {
count++;
i++;
}
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();t2.start();
t1.join();t2.join();
System.out.println(count);
}
}
那么,在什么场景下适合使用volatile呢?该文章总结了几种场景:
- status flags
- one-time safe publication
- independent observations
- the “volatile bean” pattern
- The cheap read-write lock trick
对这些场景下volatile的使用我掌握的还不是很透彻,希望自己以后再看开源代码的时候遇到volatile的时候会重点去关注一下。
参考文献
[2] Java 理论与实践: 正确使用 Volatile 变量
[3] jsr133
[4] Java内存访问重排序的研究