1. Client端,两种消费方式
- Push 模式
1
2
3
4
5
6
7
8consumer.subscribe("TopicTest1", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf(Thread.currentThread().getName() + " Receive New Messages: " + msgs + "%n");
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
应用代码注册一个监听器,Client 在拿到消息后主动 call 这个listener.
- Pull 模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("TopicTest1");
for (MessageQueue mq : mqs) {
SINGLE_MQ:
while (true) {
try {
PullResult pullResult = consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);
System.out.printf("%s%n", pullResult);
putMessageQueueOffset(mq, pullResult.getNextBeginOffset());
switch (pullResult.getPullStatus()) {
case NO_NEW_MSG:
break SINGLE_MQ;
case FOUND:
case NO_MATCHED_MSG:
case OFFSET_ILLEGAL:
default:
break;
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
应用代码主动去 Client Pull 消息,Pull 模式还支持 callback 的方式。这个 callback 和 Push 模式中的 callback 不同的是:Pull 模式需要应用代码主动去 call pull 接口,拿到消息只回调一次,Push 模式则是 Client 会有线程一直去拿消息,只要有消息就会一直回调。
Pull 和 Push 是针对应用系统来说的,Push 模式消息消费及时,一有消息就通知应用系统,缺点是不知道应用系统的消费能力,消息多的话一直Push应用系统会来不及处理,Pull 模式不会有这种情况,但是缺点就是消息消费可能不够及时,需要应用代码自己去维护消费频率,offset等。不管是 Pull 模式还是 Push 模式,对于 Client 模块来说,本质上都是 Pull 模式,它去 Broker Pull Message,而不是 Broker 主动 Push 给 Client.
2. Push消费过程
Pull 的过程比较简单(因为应用代码要去做比较多的事情),所以这里我主要来梳理一下 Push 方式的整个过程。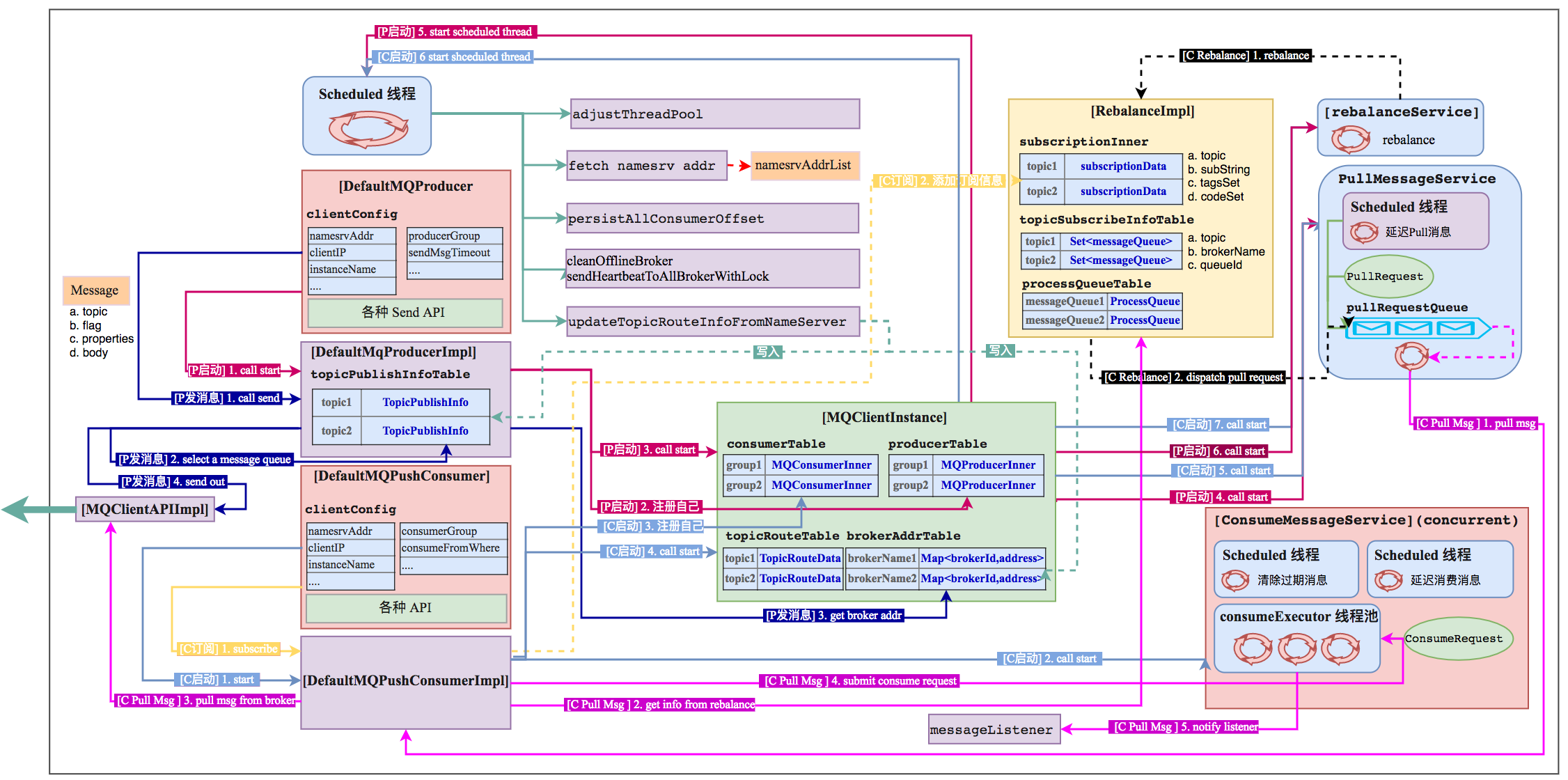
2.1 负载均衡
Consumer 负载均衡的核心问题就是如何均衡的把多个 MessageQueue 分给多个 Consumer. rocketmq-client 在启动过程中会启动一个线程按一定的频率做rebalance. Rebalance 维护了三个关键的Map:1
2
3Map<String /* topic */, SubscriptionData> subscriptionInner
Map<String/* topic */, Set<MessageQueue>> topicSubscribeInfoTable
Map<MessageQueue, ProcessQueue> processQueueTable
Conusmer 在订阅消息的时候,会往 subscriptionInner 新增数据:1
2
3
4
5
6public void subscribe(String topic, String subExpression) {
...
SubscriptionData subscriptionData = FilterAPI.buildSubscriptionData(this.defaultMQPushConsumer.getConsumerGroup(), topic, subExpression);
this.rebalanceImpl.getSubscriptionInner().put(topic, subscriptionData);
...
}
Scheduled线程在updateTopicRouteInfoFromNameServer的时候会去新增/更新 topicSubscribeInfoTable.
doRebalance的过程会遍历subscriptionInner中的所有topic, 针对每个topic做负载均衡,处理的时候分为 CLUSTERING 和 BROADCASTING 两种模式。
- CLUSTERING
- 从 topicSubscribeInfoTable 中获取这个 topic 的所有 messageQueue。
- 从 broker 获取订阅这个 topic 的所有 client, 即一个 clientId的 list。
- 有了(1)和 (2), 就可以获得应该分配给当前 consumer 的 messageQueue 了,具体的分配策略可以看 AllocateMessageQueueStrategy 的各种实现。
- 拿到分配结果后,就可以去更新 processQueueTable 了,如果是新增的 messageQueue,就会构建一个 PullRequest 添加到 LinkedBlockingQueue
pullRequestQueue 中去。
1 | { |
- BROADCASTING
如果是广播,其实也就没什么好负载均衡了,就是把 topicSubscriptionInfoTable 中的所有 MessageQueue 都放到 processQueueTable 中去。因为当前 consumer 需要消费该 Topic 的所有消息。
2.2 PullMessageService
PullMessageService 也是一个单独的线程,会不停的从 LinkedBlockingQueue
- FOUND, 找到消息了,将消息放到 ProcessQueue的lockTreeMap中,提交给 consumeMessageService
- NO_NEW_MSG,没有新消息,调整offset, 重新将pullRequest放到pullRequestQueue中,接着轮询。(这其实是一个长轮询的过程,Consumer在Pull的时候会设置timeout,也会传给broker一个suspend的时间,关于长轮询, 殷琦同学的Long Polling长轮询详解 和 Long Polling长轮询实现进阶 介绍的很清楚)
- NO_MATCHED_MSG, 没有匹配的消息,调整offset, 重新将pullRequest放到pullRequestQueue中
2.3 ConsumeMessageService
ConsumeMessageService 有 ConsumeMessageConcurrentlyService 和 ConsumeMessageOrderlyService 两种。
ConsumeMessageConcurrentlyService 里定义了一个 ThreadPoolExecutor,PullMessageService 拿到消息后会封装成 ConsumeRequest 丢给该线程池, ConsumeRequest会做以下操作:
- 有hook则执行 before Hook
- 回调应用代码注册的消息监听器
- 有hook则执行 after Hook
- ConsumerStatsManager做一些统计
ConsumeMessageOrderlyService 在消费的时候会按 MessageQueue 加锁,这样就能保证一个MessageQueue中的消息是按序消费的。配合 Producer 的按序发送消息,就可以保证消息的顺序了。
Reference
-
以上所有扯淡都是基于源码 https://github.com/apache/incubator-rocketmq (tag:rocketmq-all-4.1.0-incubating) 所贴代码有所删减。