这周工作空闲时间把之前从知乎爬下来的用户数据做了简单的分析和可视化,分析就用了mongodb的一些简单的聚合命令,可视化用的是Echart. 本来是可以看动态效果的,这里就只能贴几张图了。只是实现功能而已,图中展现的数据不一定准确,用的数据量有限,并没有统计我抓下来的所有数据。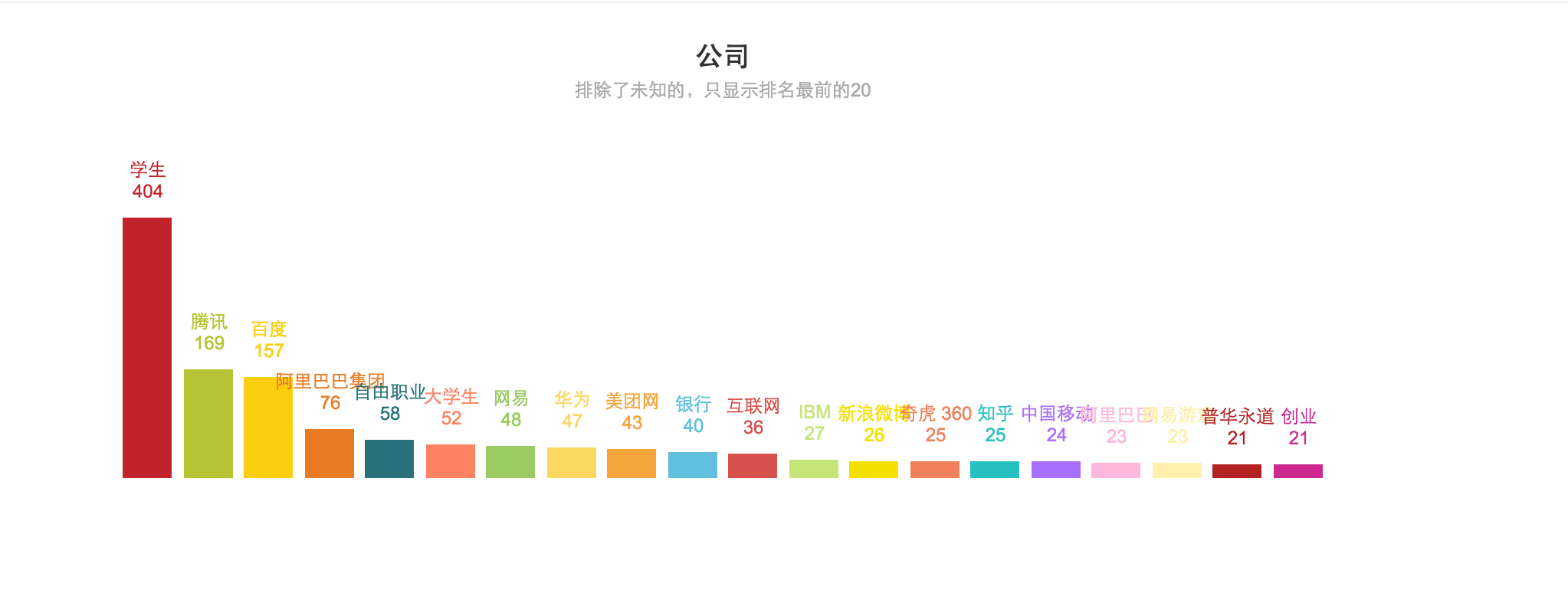
分布式爬虫之BloomFilter
分布式爬虫小记
前言
距离上一篇博客不知不觉居然过了一个月了,说来惭愧,上篇博客中还说要每周都记录一点东西,前两周刚好周末有点事情加上自己还是懒惰了点,心里给自己一个接口就这么过去了。但这段时间还是有点收获的,利用业余时间玩了玩爬虫,不像之前都只是看文章并没有去实践。我一直觉得不能将自己知道的东西写出来,并让别人看得懂,就不能算真正掌握。今天就试着对我过去这段时间学习的爬虫做个总结,看看自己是否真的掌握了。写着写着,感觉废话有点多,倒不像一篇技术博客了,其实本来也不是,算是我自己的日记吧。
说起爬虫,经常在微博上看到梁斌爬些语料贡献给学术界或者卖点钱做慈善,我也曾想过玩玩,但一直不知道爬些什么数据好,于是去知乎上搜了搜,看到这篇文章—-一个知乎重度用户眼中的知乎,觉得我也可以试试,爬些知乎的用户信息,做些简单的数据分析,数据可视化,看看是不是真的有一半用户的程序员,哈哈