干货都在参考文献里,我只是总结了一下我自己吸收的。
分布式ID
分布式ID,可以理解为分布式系统的数据的唯一标识。概况起来,通常需要满足以下几个条件:
- 唯一性
- 有序
对数据库中的数据按时间进行排序是很常见的需求,通常在表中有GMT_CREATE和GMT_MODIFIED字段,通过在这些字段上建立普通索引(non-cluster index),可以在一定程度上加快排序的速度。但相比聚集索引,普通索引的访问效率还是比较慢的,所以可以通过在主键上建立聚集索引来实现排序。 - 有意义的
比如,ID中可能会包含一些业务信息,用于标识所属业务。 - 可反解
一个 ID 生成之后,就会伴随着信息终身,排错分析的时候,我们需要查验。这时候一个可反解的ID可以帮上很多忙,从哪里来的,什么时候出生的。就好比身份证,我们从身份证号上可以分析出这个人的出身年月。
常见方法
使用数据库的auto_increment
- 优点:
- 简单
缺点:
- 只能满足唯一性和有序,不能生成有业务含义和需要可反解的ID
- 可用性差,单机嘛,挂了就不可用了
- 可扩展性差,ID生成是写操作,单个数据库的写性能是有限的,需要扩展,这种方案没啥可扩展性。
改进方案:
- 增加主库,避免写入单点,提高性能
- 数据水平切分,保证各库生成的ID不重复
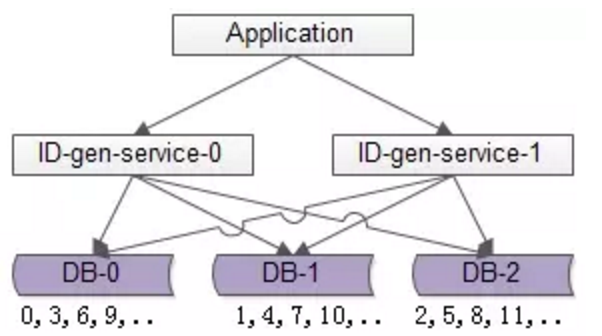
如图所示,可以增加2个库,每个库设置不同的ID起始值,以及相同的增长步长。这种方案虽然提高了可用性和可扩展性,保证了唯一性,但是不能保证有序,因为可能先调用了DB-0,生成0,3,然后调用DB-1生成1.
- 优点:
- 批量ID生成服务
数据库使用双master保证可用性,数据库中只存储当前ID的最大值,例如0。ID生成服务假设每次批量拉取6个ID,服务访问数据库,将当前ID的最大值修改为5,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4,5这些ID了,当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6了。为了解决服务单点问题,增加了一个备用服务,当主服务挂掉时,备服务自动切换(业界应该有实现方案,我还不懂)。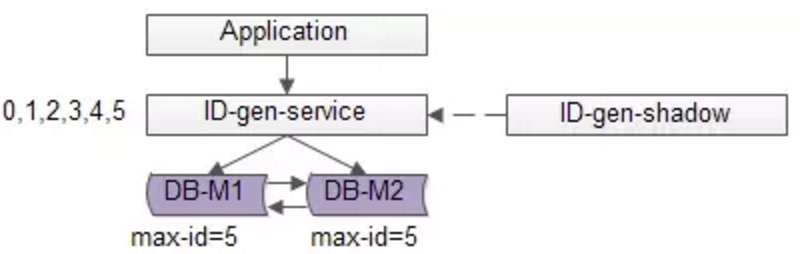
- 优点:
- 高可用
- 缺点:
- 只能满足唯一性和有序,不能生成有业务含义和需要可反解的ID
- 如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,5,数据库中max-id是5,分配到3时,服务重启了,下次会从6开始分配,4和5就成了空洞,不过这个问题也不大)。如果用的是高可用的第三方缓存来保存这些中间值,应该可以避免这个问题。
- 性能有限,无法水平扩展。
- 优点:
- UUID
- 优点:
- 简单
- 快,无性能问题
- 缺点
- 只能保证唯一性(其实也不一定唯一,只是重复的概率很小[1]),其它都保证不了,没有业务含义,无序
- 比较长,占用空间大。
- 优点:
- 类snowflake算法
snowflake是twitter开源的分布式ID生成算法,其核心思想是:一个long型的ID,使用其中41bit作为毫秒数,10bit作为机器编号,12bit作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
借鉴snowflake的思想,结合各公司的业务逻辑和并发量,可以实现自己的分布式ID生成算法。比如可以在中间加入2个bit的业务标识等。具体位数要怎么安排需根据具体业务要求来计算。如果要达到精确的有序,就要对 Sequence 进行并发控制,性能上肯定会打折。所以经常会有的一个选择就是,在这个秒的级别上不再保证顺序,而整个 ID 则只保证时间上的有序,也叫做K-sorted。后一秒的 ID肯定比前一秒的大,但同一秒内可能后取的ID比前面的号小。
这里有个需要注意的地方是,就是分配给time的bit位数,这个time使用的单位有关系。那时间用秒还是毫秒呢?其实不用毫秒的时候就可以把空出来的10bit 送给 Sequence,但整个ID 的精度就下降了。峰值速度是更现实的考虑。Sequence 的空间决定了峰值的速度,而峰值也就意味着持续的时间不会太久。这方面,每秒100万比每毫秒1000限制更小。
参考:
[1] Universally unique identifier
[2] 细聊分布式ID生成方法
[3] 业务系统需要什么样的ID生成器
[4] Introducing Icicle: a distributed, k-sortable unique ID generation system using Redis and Lua
[5] 基于redis的分布式ID生成器
[6] Sharding & IDs at Instagram
[7] MySQL :: There is a Sequence to Generate Unique Value for Sharding Key
[8] OneProxy :: 如何生成生成分库分表下的主键值?可以使用分布式Sequence服务!