缓存是提高系统性能的利器,我们开发中常用的就是本地缓存和分布式缓存,对于单机的、数据量不大的数据,可以用HashMap自己实现一个简单的缓存,也可以用Guava cache来实现。对于分布式缓存,现在业界常用的都是基于redis, memcached,还有阿里的tair来做的。下面总结一下使用分布式缓存的时候要考虑的问题。
更新策略
- LRU/FIFO等,对数据一致性要求不高;
- 超时淘汰,对数据一致性要求也不是很高,实现简单,像redis的话,直接对key设置一个timeout就可以了;
- 主动更新,对数据一致性要求较高。后面的总结都是针对这种主动更新来说的。
主动更新的套路
缓存架构设计细节二三事(作者:沈剑) 和缓存更新的套路(作者:陈皓) 两篇文章都介绍了如何更新缓存。前者的结论是:
- 淘汰缓存是一种通用的缓存处理方式
- 先淘汰缓存,再写数据库的时序是毋庸置疑的
后者则主张先写数据库再淘汰缓存,我这里对两种会遇到的情况做个总结,方便自己温故知新。
先淘汰缓存,后更新数据库
正常情况下不会有什么问题,如果淘汰缓存成功,更新数据库失败,也仅仅会造成一次缓存没命中,查询数据库后又会将缓存更新,不会有大问题。但是如果在下面的并发情况下: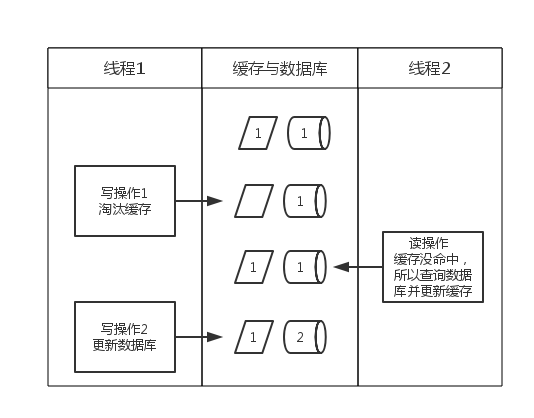
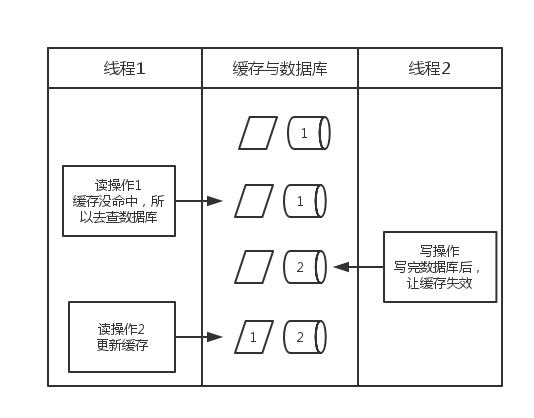
正如陈皓说的:两个线程,一个是写操作,另一个是读操作,写操作淘汰缓存后,读操作没有命中缓存,先把老数据读出来后放到缓存中,然后写操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。先更新数据库,后淘汰缓存
存在的问题:
- 沈剑在文中提到:如果更新数据库成功,淘汰缓存失败了,那么缓存中就出现了脏数据
- 如下图所示,陈皓在文中说:一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
两种方案看来都有问题,都没法做到数据的强一致,如果非要强一致,就得引入分布式事务来保证写数据库和淘汰缓存在一个事务里,这样做性能又会受到影响。所以通常是用一种主动更新策略+超时淘汰来做缓存。
缓存会遇到的一些问题
缓存使用与设计系列文章 对缓存使用中可能会遇到的问题做了很好的分析和总结。
- 穿透问题
| 解决缓存穿透 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | 1. 数据命中不高;2. 数据频繁变化实时性高 | 1.代码维护简单;2.需要过多的缓存空间;3. 数据不一致 |
| bloomfilter或者压缩filter提前拦截 | 1. 数据命中不高;2. 数据相对固定实时性低 | 1.代码维护复杂 ;2.缓存空间占用少 |
- 无底洞问题
就是缓存到了一定规模后,再加机器也没有明显的性能提升了,具体分析见缓存使用与设计系列文章 热点key问题
比如key XXX对应的数据访问量特别大,但是XXX在缓存中是有失效时间的。一旦缓存失效,会有N多线程并发的去请求数据库,然后更新缓存,这个时候会导致系统压力过大。通常有这么几种解决方法:- 加锁,同时只允许一个线程去查询数据库并更新缓存
- 缓存不加失效时间,但后台有个异步线程定期的去更新它
- 引入类似于Hystrix的熔断机制,只允许一定量的请求去请求数据库并更新缓存
雪崩问题
假设系统A调用系统B,中间用redis做缓存,通常有这么几种情况会造成雪崩:- B系统因为某种原因挂了,等B系统系统服务恢复时,cache都已经超时失效了,造成B系统过载。
- Cache系统故障,A系统的流量将全部流到B系统,造成B系统过载。
- Cache故障恢复,但这时Cache为空,Cache瞬间命中率为0,造成B系统过载。
Cache应用中的服务过载案例研究对该问题做了很详细的分析。总结一下其实就是:
- 调用方在缓存没有命中时,不要每次都去调用下游系统,比如5个线程同时没有命中,可以只有一个线程去请求,其他线程等着。
- 被调用方要做好流量控制,防止自己被压垮。