Store 在写消息之前会做一些校验(broker的角色、Topic的长度、消息Properties的长度等),然后交给 CommitLog去处理,CommitLog的整体流程如下:
- 设置一些信息到 MessageExtBrokerInner 对象中(storeTimestamp、message body CRC等)
- 获取 mappedFile,并 append消息到 mappedFile
- handleDiskFlush,刷盘
- handleHA
- deReput, 一个单独的线程,会按一定的频率去构建 consumeQueue 和 index
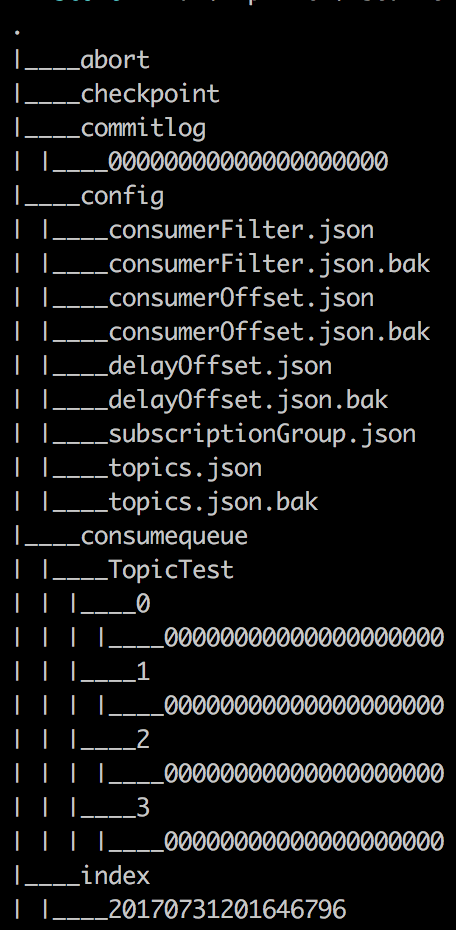
重点关注下这张图中 commitlog、consumequeue、index 的路径和文件名。
1. 【写消息】MappedFile Append Message
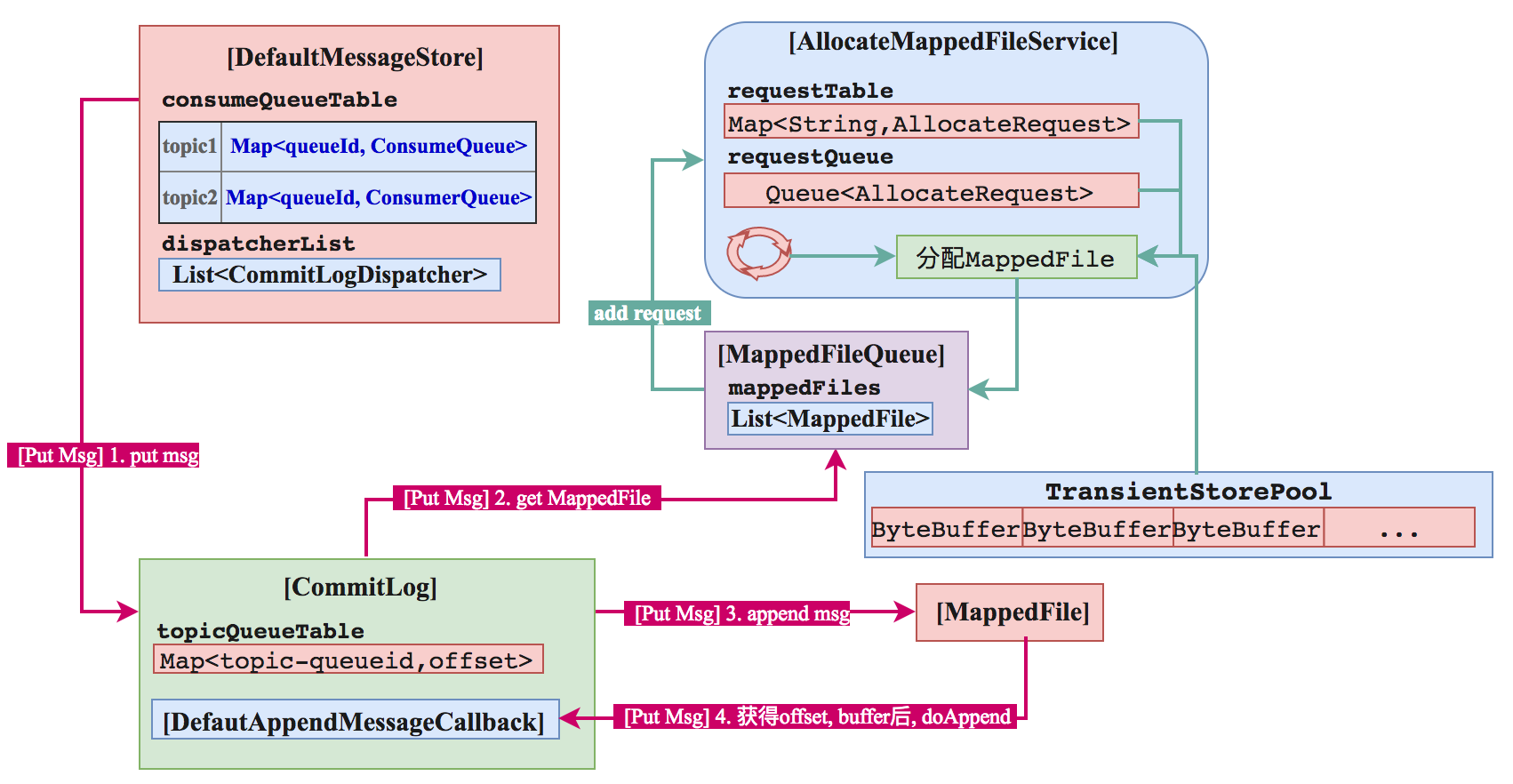
CommitLog 先从 mappedFileQueue 获取一个 mappedFile, 如果没有就新建一个。
MappedFile 的创建过程是构建一个 AllocateRequest 到队列里,AllocateMappedFileService 是一个单独线程,会不停的跑,只要请求队列里有数据,就会去执行分配工作,分配的时候有两种策略,一种是直接分配内存,一种是从TransientStorePool里获取Buffer。不同的策略在刷盘的时候也会有所区别。 MappedFile 对应的文件的存储路径为 :1
this.storePath + File.separator + UtilAll.offset2FileName(createOffset);
即MessageStoreConfig中配置的storePath + 路径分隔符 + offset格式化(20位数字),举个例子,默认配置下,第一个commitLog的路径为~/store/commitlog/00000000000000000000 . 文件的大小默认为1G,可以通过MessageStoreConfig配置:1
2// 单位为byte
private int mapedFileSizeCommitLog = 1024 * 1024 * 1024;
Message Append 到 MappedFile 是顺序写的,消费的时候是随机读的。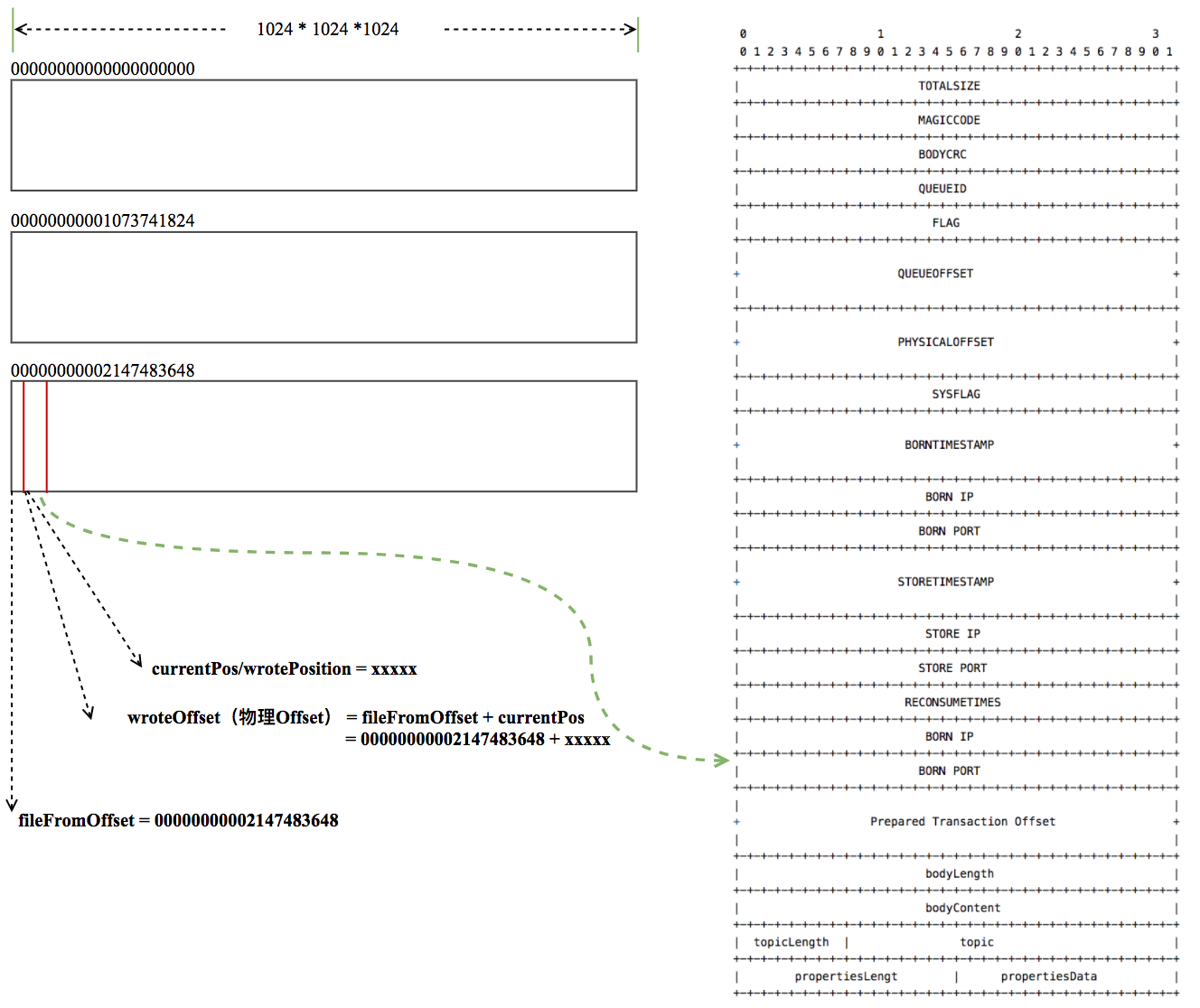
MappedFile 和物理文件是一一对应的,append的过程,消息的具体构成如图所示,大部分字段都很好理解,这里重点关注下 queueOffset 和 physicaloffset. queueOffset 是指对应的 consumeQueue 中的 offset, physicaloffset 是指该消息的物理offset,即图中的 wroteOffset, 它等于 fileFromOffset(当前mappedFile的物理offset) 加上 mappedFile 对应的 buffer 的 position(一个逻辑的offset).
2.【写消息】刷盘
Message 按照之前描述的结构写到 mappedFile(或者叫commitLog)中后,一直在内存中,只有在刷盘后才会落地。刷盘分为同步刷盘和异步刷盘两种。同步刷盘会构建一个GroupCommitRequest,交给 GroupCommitService 这个线程去处理,然后等待它刷盘完成后再返回(线程在完成刷盘后会用countDownLatch notify 等待的线程). 异步刷盘用 countDownLatch notify 负责刷盘的线程后就直接返回了。这个过程还涉及各种offset,描述起来比较复杂,水平有限,就不瞎BB了
3. 【写消息】HA
Broker 有这几种角色ASYNC_MASTER/SYNC_MASTER/SLAVE. 消息肯定都是写到MASTER上的,然后同步给SLAVE。同步的方式分为SYNC和ASYNC两种,针对ASYNC的,消息写完后就直接返回了,后台线程会去做同步的操作。对于SYNC的方式,要等到同步完成后才返回。这两种方式也称作异步复制和同步双写。 HA的整个过程只在 store 模块做的,是基于 JDK 的 nio来写的,没有依赖 remoting 模块。
4. 【写消息】Reput
ReputMessageService 也是一个单独的线程,它负责构建 ConsumeQueue 和 Index。
4.1 ConsumeQueue
ConsumeQueue的结构如图: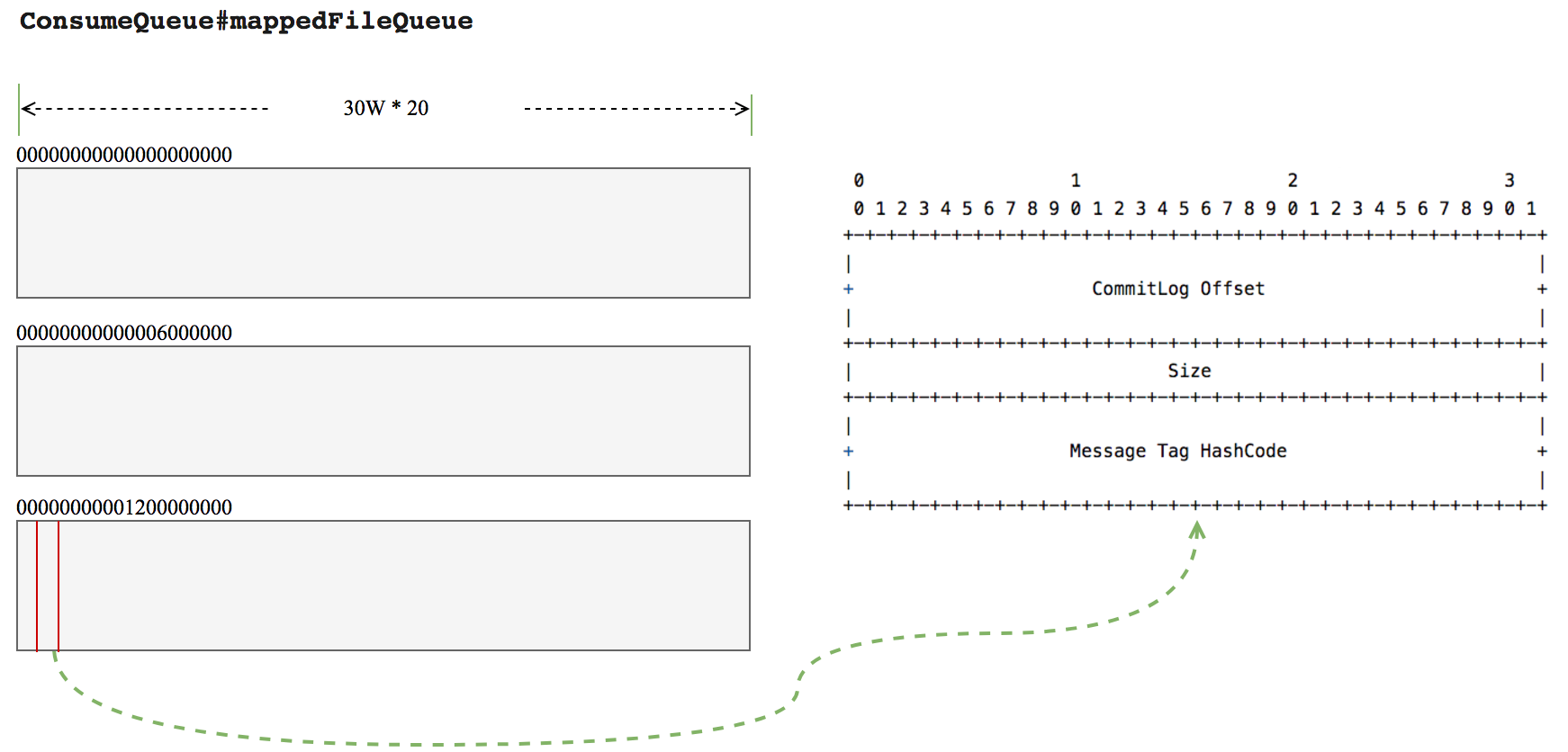
ConsumeQueue 对应的文件的存储路径为 :1
/store/consumequeue/${topicName}/${queueId}/${fileName}
ConsumeQueue 文件的默认大小为30W 20,20是 queue中 每个存储单元的大小,每个存储单元对应 CommitLog 中的一个消息。即一个 ConsumeQueue 文件可以对应 30W 个消息。一个 CommitLog 的大小为 1G, 假设每个消息的大小为 1 K,则一个 CommitLog 可以存储 1024 1024 个消息,那就需要 1024 * 1024 / 30W,向上取整4个ConsumeQueue. 所以,每个Topic可能有多个ConsumeQueue, 每个queue有自己的id, 对应的 fileName 为它的offset.
ConsumeQueue 中每个单元的大小为20字节,包含 commitLog offset/Size/Tag hashCode/ 三个字段,前面两个字段可以用于去 commitLog中查找真正的消息内容,最后一个可以用于在broker端根据tag过滤消息,当然,这个过滤不是完全靠谱的,不同的tag可能有相同的hashCode,Consumer端还可以根据自己的需要做进一步精确的过滤。
4.2 Index File
图片来源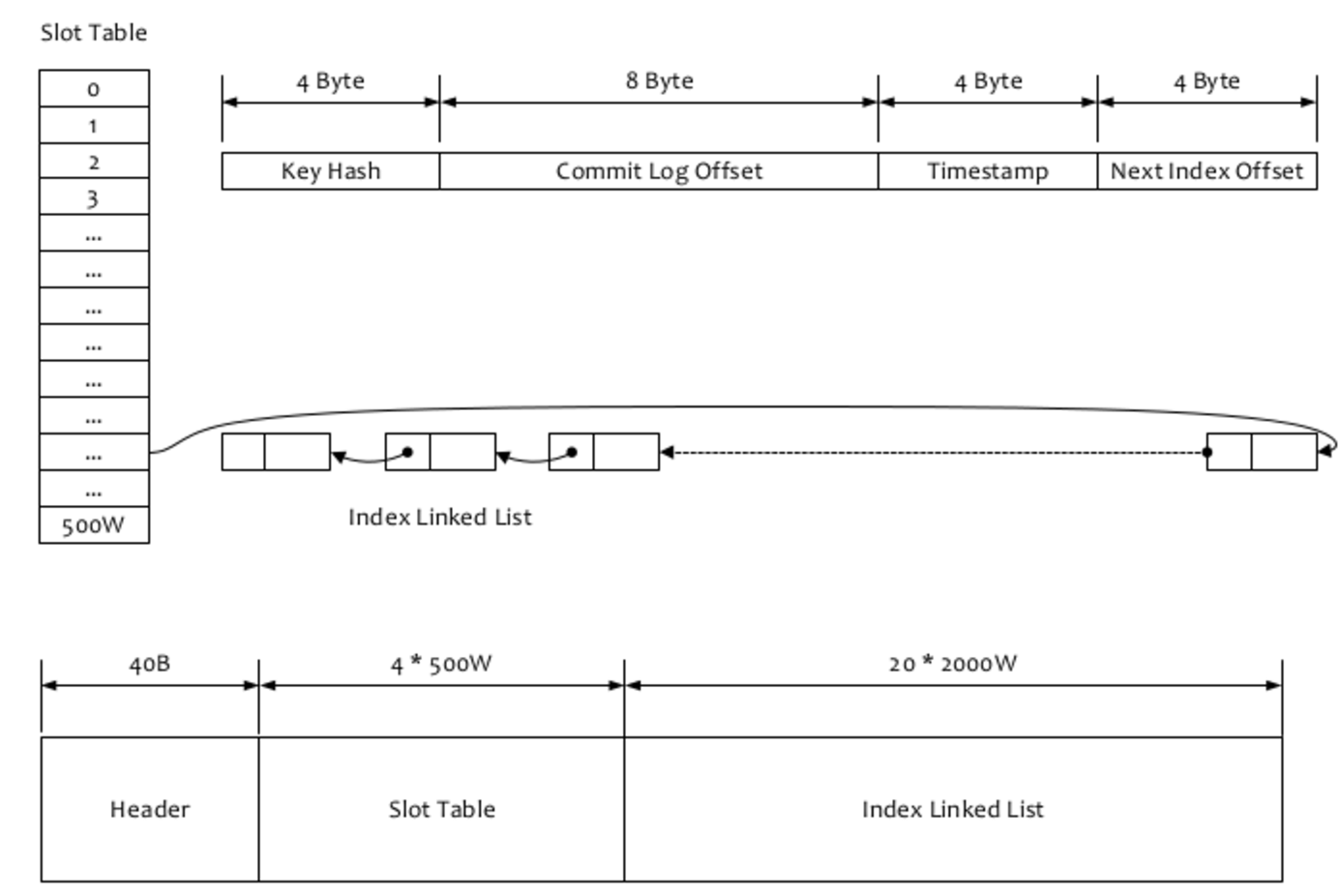
首先会去 IndexFileList 中获取一个最后一个 IndexFile, 判断它有没有被写满,如果满了就新建一个,否则就返回它。IndexFile的文件名是根据时间戳生成的。
如果消息的properties中设置了 UNIQ_KEY 这个属性,就用 topic + “#” + UNIQ_KEY的value 作为 key 来做put操作。如果消息设置了 KEYS 属性(多个KEY以空格分隔),也会用 topic + “#” + KEY 来做索引。
- 计算槽位,slotPos = hash(key) % hashSlotNum, hashSlotNum 默认是500W.
- 计算当前这个槽位的绝对地址(或者说在当前这个mappedFile中的内存地址) absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize. headerSize 是 40个字节,按顺序依次保存这几个信息:
- Long beginTimestamp(8 Byte)
- Long endTimestamp(8 Byte)
- Long beginPhyoffset(8 Byte)
- Long endPhyoffset(8 Byte)
- Integer hashSlotcount(4 Byte),看了代码,好像和indexCount的数量是一致的,不知道有啥用
- Integer indexCount(4 Byte), 索引的个数
- 读取当前这个槽位的值 slotValue,如果之前之前这个槽位没有被占用过(Hash冲突的情况),这个值会是0.
- 计算真正写索引数据的地址, absIndexPos = IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum hashSlotSize + this.indexHeader.getIndexCount() indexSize;从absIndexPos这个位置开始,写入索引数据。
索引数据包括 Key Hash/CommitLog Offset/Timestamp/NextIndex offset 这四个字段,一共20 byte. NextIndex offset 即前面读出来的 slotValue, 如果有 hash冲突,就可以用这个字段将所有冲突的索引用链表的方式串起来了。Timestamp 记录的是消息storeTimestamp之间的差,并不是一个绝对的时间。整个Index File的结构如图,40 Byte 的Header用于保存一些总的统计信息,4 500W的 Slot Table并不保存真正的索引数据,而是保存每个槽位对应的单向链表的头。20 2000W 是真正的索引数据。即一个 Index File 可以保存 2000W个索引。
5. 【读消息】
如果走的是PullMessageProcessor, 读取消息的过程就是用 queueId 和 queueOffset 找到 consumeQueue 中的一条记录,根据其中的 tag hashcode 做过滤,如果要读,就用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录。
如果走的是QueryMessageProcessor, 读取消息的过程就是用 topic 和 key 找到 IndexFile 中的一条记录,根据其中的 commitLog offset 去读取真正的消息。
走哪个 Processor 取决于应用代码使用的是 client 模块提供的哪个 API.
Reference
-
以上所有扯淡都是基于源码 https://github.com/apache/incubator-rocketmq (tag:rocketmq-all-4.1.0-incubating) 所贴代码有所删减。